In our last posts you learned about the design of a continuous delivery pipeline as well as versioning of microservices. This last part of our blog post series “The Continuous Delivery Pipeline of our Microservices Architecture” deals with handling failures in the continuous delivery pipeline.
What happens if a pipeline build fails?
A continuous rollout of new features isn’t free from any failures during the progress of deployment. The reasons for failing can be related to different issues. Different tests in the separated stages assure the confidence in the quality and reliability of the software.
Scenarios for failures in the displayed CDP
- During the build or the acceptance stage
Within the build stage failures will more often occur with regards to testing pull requests from GitHub. These can be easily solved by committing fixes to the given branch. Failures in the acceptance stage occur during the installation of a new image or by running the API tests. Fixes for failures can be applied in a similar way to the build stage.
- In the pre-production stage
In this case there is a ‘no going back’ strategy. Instead of rolling back changes we are going to apply a fix for the failure immediately, because on the one hand it is easy to roll back changes in the code base, but on the other hand it is very difficult to roll back database changes or manipulations to data in the environment in general.
So in case of a failure, the pre-production stage will be automatically locked to avoid any other builds passing over from the acceptance stage into pre-production. The implemented locking mechanism not only triggers a block to avoid further builds passing over into the pre-production stage, but also triggers a notification to developer tools to inform about a failure in the pipeline (e.g. email). As long as the lock on the pre-production stage is set, a visual banner will be displayed in the pipeline job. Developers are now in charge to check the failure and provide a fix. This has to be done immediately to prevent the pipeline from being blocked for other builds.
Fast-Lane concept
To deploy this fix to the current status of the microservice we use a so called ‘Fast-Lane’ concept. This concept describes a second pipeline, which is running the same stages as the CDP itself to deploy the changes to fix the current pipeline issues.

The next image shows a CDP with currently seven builds running. To explain the concept, the build of the service S1 is going to fail in pre-production stage. To roll out a fix to solve the problem some details have to be considered. At this point of time when a pipeline build fails it is possible that other features for the same microservice are already running in any stage of the CDP or are queued up to pass over into the acceptance or pre-production stage. This is represented by the other S1 builds in queue 1 and 2 and in the acceptance stage. This means, that these changes are therefore already merged on the master branch of the related GitHub repository. To apply a fix for the current failure therefore not only includes the required changes but also all changes already merged on the master branch. The applying of the fix will be on a fast-lane that is able to overtake all other current builds in the CDP:
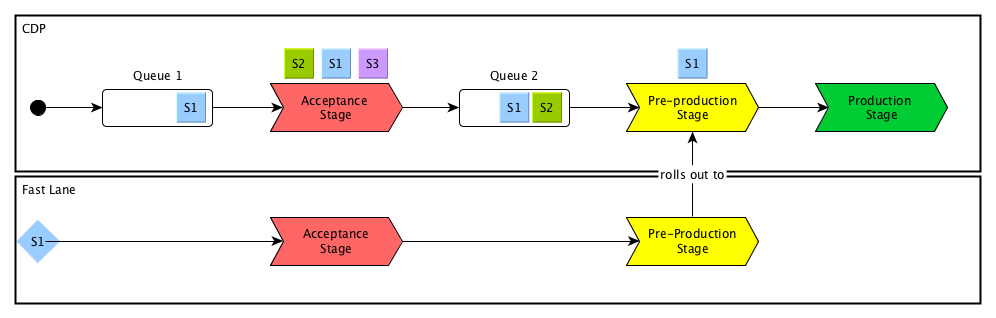
After successfully passing the acceptance and pre-production stage in the fast-lane, these changes are rolled out to the actual pre-production stage of the CDP. To avoid changes of the same service to be rolled out again it is necessary to cancel builds regarding the same microservice the fix was deployed with. Hence, all running builds of the S1 service need to be removed in the CDP. Now the pre-production stage gets unlocked and the next build is able to pass over:
