In his fabulous blog post [On the way to full stack ECMAScript 6][prev-blog-post] my dear colleague Paolo described the benefits that we gain from migrating to ES6. But as always, where there is light there is shadow and so today I want to address one loose end of the last post. Namely, that is the problem of code coverage with ES6. See this Demo Project to try out everything explained in this post yourself.
Disclaimer: This is not a isparta bashing post. Isparta served use very well the last months, but it is discontinued and I want to discuss some pitfalls and show a new kid on the block that solves many of these.
Coverage reports
As mentioned in the last post we are currently using isparta to have our coverage reports on the original ES6 code rather than on the transpiled ES5 code. This works quite ok but has some serious drawbacks. You see what is covered and what not in the original ES6 code, but the statement/branch/function numbers are way higher than one would expect (and so skew the results). With isparta you basically get normal Istanbul instrumentation on ES5 that is then mapped back via the sourcemaps you got from transpiling ES6 to ES5. Let me show two examples, why this is problematic:
Imports
Imports are already hard to properly reflect when using isparta. Look at the following simple ES6 code sample:
// greeter.js
export default function greeter (name) {
return `Hello, ${name}!`
}// chuckNorrisGreeter.js
import greeter from './greeter'
export default function chuckNorrisGreeter () {
return greeter('Chuck Norris')
}Taking a look at chuckNorrisGreeter.js one would expect at most three statements (or two, since imports are not really statements from an execution point of view) and zero branches. Using isparta we first transpile ES6 to ES5 (with source maps) and then do ordinary instrumentation in the ES5 realm. So Istanbul sees this:
// chuckNorrisGreeter.js (ES5)
'use strict';
var _greeter = require('./greeter');
var _greeter2 = _interopRequireDefault(_greeter);
function _interopRequireDefault(obj) {
return obj && obj.__esModule ? obj : { default: obj };
}
(0, _greeter2.default)('Chuck Norris');Well, nope. This are more statements and there is at least one branch due to the ternary.
JSX
With JSX (which makes a big piece of our project), the numbers are even worse. As you might know JSX transpiles into nested React.createElement calls. The following example shows a simple and pure React component that just renders a list of strings into a list of <div/>s:
// ListView.jsx
import React, {Component, PropTypes} from 'react'
export default class ListView extends Component {
static get propTypes () {
return {
items: PropTypes.arrayOf(PropTypes.string).isRequired
}
}
render () {
return (
<div className='list-view'>
{this.props.items.map((item, index) =>
<div key={index} className='list-view-item'>
{item}
</div>
)}
</div>
)
}
}At least IMHO this component can be considered to be very simple. No different cases to handle, no interaction logic. Simply an input array of strings and some HTML stuff as output. So let’s look at the transpiled source:
// ListView.jsx (ES5)
'use strict';
Object.defineProperty(exports, "__esModule", {
value: true
});
var _createClass = function () { function defineProperties(target, props) { for (var i = 0; i < props.length; i++) { var descriptor = props[i]; descriptor.enumerable = descriptor.enumerable || false; descriptor.configurable = true; if ("value" in descriptor) descriptor.writable = true; Object.defineProperty(target, descriptor.key, descriptor); } } return function (Constructor, protoProps, staticProps) { if (protoProps) defineProperties(Constructor.prototype, protoProps); if (staticProps) defineProperties(Constructor, staticProps); return Constructor; }; }();
var _react = require('react');
var _react2 = _interopRequireDefault(_react);
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
function _possibleConstructorReturn(self, call) { if (!self) { throw new ReferenceError("this hasn't been initialised - super() hasn't been called"); } return call && (typeof call === "object" || typeof call === "function") ? call : self; }
function _inherits(subClass, superClass) { if (typeof superClass !== "function" && superClass !== null) { throw new TypeError("Super expression must either be null or a function, not " + typeof superClass); } subClass.prototype = Object.create(superClass && superClass.prototype, { constructor: { value: subClass, enumerable: false, writable: true, configurable: true } }); if (superClass) Object.setPrototypeOf ? Object.setPrototypeOf(subClass, superClass) : subClass.__proto__ = superClass; }
var ListView = function (_Component) {
_inherits(ListView, _Component);
function ListView() {
_classCallCheck(this, ListView);
return _possibleConstructorReturn(this, Object.getPrototypeOf(ListView).apply(this, arguments));
}
_createClass(ListView, [{
key: 'render',
value: function render() {
return _react2.default.createElement(
'div',
{ className: 'list-view' },
this.props.items.map(function (item) {
return _react2.default.createElement(
'div',
{ className: 'list-view-item' },
item
);
})
);
}
}], [{
key: 'propTypes',
get: function get() {
return {
items: _react.PropTypes.array.isRequired
};
}
}]);
return ListView;
}(_react.Component);
exports.default = ListView;Wow! This just exploded into a huge pile of complexity. If you run the test suite of the
Demo Project this component is included twice as ListView and as ListViewUntested. Both have the exact same source code, but for the later the test is skipped, so its definition is parsed but the component is never actually mounted, hence completely untested. So we would expected, that the former has a much higher coverage, right? Again, nope:
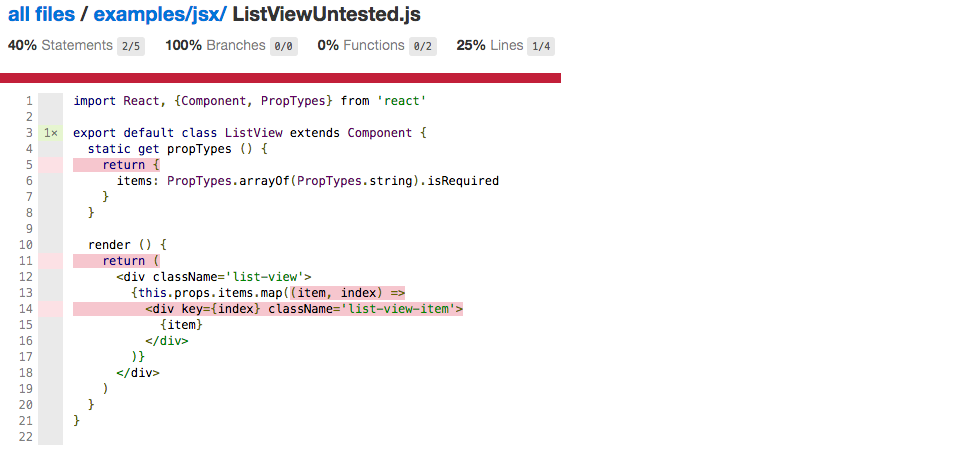
| Total | Coverage ListView |
Coverage ListViewUntested |
|
|---|---|---|---|
| Statements | 44 | 44 (100%) | 41 (93%) |
| Branches | 31 | 31 (100%) | 31 (100%) |
| Functions | 12 | 12 (100%) | 11 (92%) |
So if your project would only consist out of ListViewUntested, then dispite the fact, you have basically zero coverage, isparta says you are fine. In a project that has many React components this makes the whole coverage report completely pointless. Having React components (even if they are quite simple) pushes up the numbers so much, that other potential untested code just disappears.
Solution
There is a new project since February, that integrates the instrumentation directly into Babel, called babel-plugin-__coverage__. For installation instructions consult the website or take a look into the Demo Project. It works with Karma for client-side testing and with nyc for server-side testing. It is mounted as a Babel plugin and instruments the code before transpiling. This makes the numbers reflect the actual code much better.
Let’s again look at the table above, but this time with the numbers from the new instrumenter:
| Total | Coverage ListView |
Coverage ListViewUntested |
|
|---|---|---|---|
| Statements | 5 | 5 (100%) | 2 (40%) |
| Branches | 0 | - | - |
| Functions | 2 | 2 (100%) | 0 (0%) |
The two covered statements in ListViewUntested.jsx are the export default function and the extends Component part. This is true. Just by importing the file we have already executed these two statements. Apart from the coverage the overall numbers now match the actual code.
TL;DR
When using ES6 in combination with code coverage reports, then isparta can help with one thing: Seeing which code is not covered. It cannot help with answering the question how good the overall code coverage is. The project babel-plugin-__coverage__ is a new solution to this problem that can give you both. Especially when also using React the numbers get way more accurate.
Code coverage with isparta
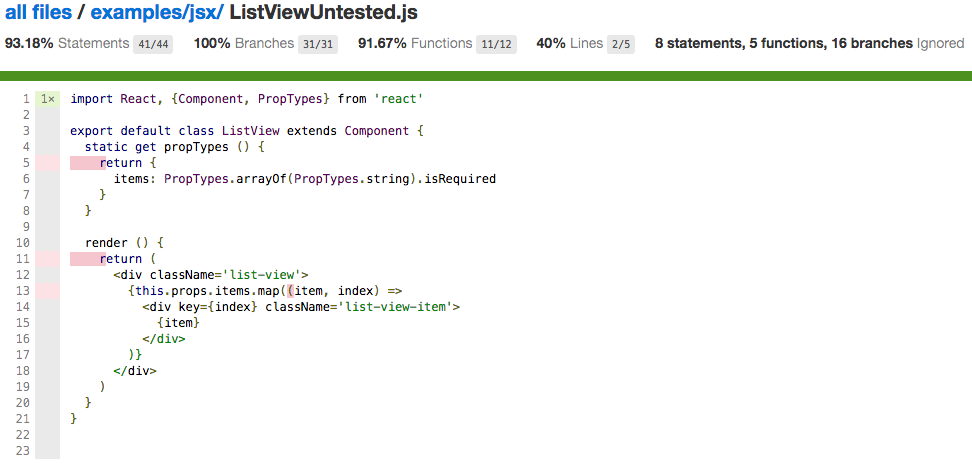
Code coverage with babel-plugin-__coverage__