As ePages heads towards a new microservice-based architecture, new challenges arise. In this kind of architecture, there are a lot of services, which are usually deployed redundantly for high availability. But from a client perspective, all these service instances should be transparent. The client should not need to care about multiple instances of a service, their different locations on the network or if they are operational, down for maintenance or in a failure state. A client should only need to deal with a single address of the service.
The solution to this challenge is Service Discovery. It is the means by which any service is able to find other services without the need to know about the actual location or other details. In our solution, Service Discovery means that you only need to know a generic URI to communicate with other REST-based services (or even some infrastructure components like message brokers).
How does it work?
A service discovery solution usually consists of three core building blocks:
- A service registry which holds the data about currently available services and instances
- A health-check mechanism to monitor service health
- A lookup or routing mechanism to connect to services
Service Registry
At the heart of the service discovery infrastructure, there is a so-called service registry. This registry has the knowledge about all available services and their instances. It gains this knowledge by providing an API to register and deregister hosts or service instances, so the services have a central point to make themselves available to the public.
Consul
We chose Consul as our service registry implementation. Consul provides the core functionality of a service registry by utilising an agent-based setup. This means, an agent, which is kind of a daemon process, runs on every machine that provides services. Here is a short abstract of Consul’s introduction documentation to get to know the most important parts:
Consul is a distributed, highly available system. […] Every node that provides services to Consul runs a Consul agent. Running an agent is not required for discovering other services or getting/setting key/value data. The agent is responsible for health checking the services on the node as well as the node itself. The agents talk to one or more Consul servers. The Consul servers are where data is stored and replicated. The servers themselves elect a leader. […] Components of your infrastructure that need to discover other services or nodes can query any of the Consul servers or any of the Consul agents. The agents forward queries to the servers automatically.
For more details, see the full introduction and the in-depth architecture overview on the Consul web site.
Health-Checks
The data inside the service registry only provides real value if it is up to date. Just knowing there once was a service available at a certain location is not enough. Therefore, checking the availability or health status of all service instances is crucial for service discovery.
In our setup, the health checking is also done by Consul. The servers check the general availability of the agents, and therefore the hosts. In addition, you can register different types of service checks with an agent, which then performs these checks against the services registered locally in fixed intervals. Whenever such a check fails, the according service or host will be marked as unavailable, and therefore the service registry will no longer promote the faulty instance any longer.
Lookup / Routing
The third major building block is a component, which is able to look up or route requests to an appropriate service instance, given an identifier for the target service. With this identifier, the clients should either receive an actual service instance address to connect to, or have its requests routed transparently to the service instance.
We decided for the routing solution, to keep the logic and also library dependencies out of the services. As the identifier, we use the first path element of any request URI, which means that a request to http://insert.hostname.here/myservice/recource1 will be routed to an appropriate service instance of the myservice service.
With this naming schema defined, the actual routing is done by HAProxy, a reliable, high performance TCP/HTTP load balancer. It is configured by a process called consul-template, which queries the information about available service instances from Consul and applies it to a provided template, in this case a template HAProxy configuration file, and (gracefully) restarts HAProxy afterwards.
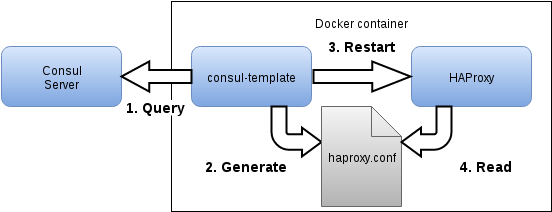
Now that we have this logic in place, HAProxy routes any incoming request to the most appropriate instance of the service given by the first path element of the request. The determination of the most appropriate instance of the service can be decided by the various load balancing features of HAProxy.
Dynamic Service Registration
So far, service discovery works fine, but how do the services register with the Consul agent on the hosts on which they are started? To solve this, we introduce another component, Registrator. This is a so-called service registry bridge for Docker. What it actually does is nicely summarised on their website:
Registrator automatically registers and deregisters services for any Docker container by inspecting containers as they come online. Registrator supports pluggable service registries, which currently includes Consul, etcd and SkyDNS 2.
Running Registrator as an additional Docker container on each host, it automatically registers new containers with the local Consul agent, and therefore makes them publicly available. Customisations, like providing the service name to be used, health check details or add-on data (tags) for a given instance can be provided in the usual Docker way by passing environment variables to the docker run command.
Conclusion
The Service Discovery solution described in this post provides all the features we need so far. There are other, similar solutions out there, but with our choice, we are also able to cover other aspects of the microservice architecture with the same technology, which is a big plus for this solution.
About the author
